この方法では
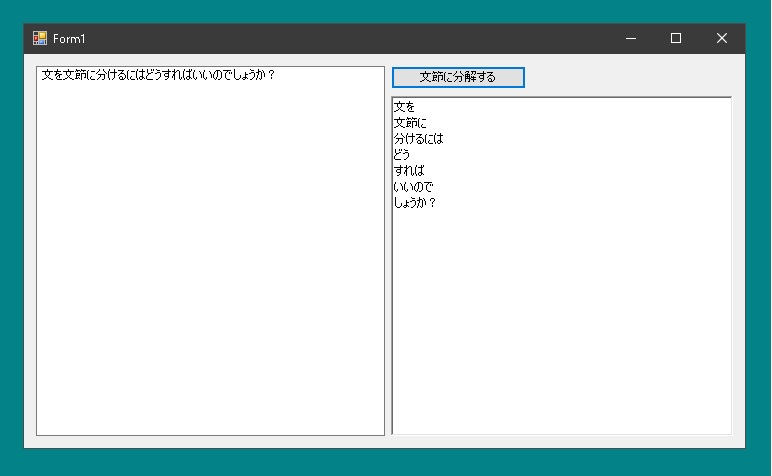
文を文節に分けるにはどうすればいいのでしょうか?
は
文/を/文節/に/分ける/に/は/どう/すれ/ば/いい/の/でしょ/う/か/?
とずいぶん細かく分かれてしまいます。これを
文を/文節に/分けるには/どうすれば/いいのでしょうか?
とわけるにはどうすればいいのでしょうか?
Yahoo! JAPANが提供するテキスト解析WebAPIには「日本語係り受け解析」があります。これをつかうと日本語文の係り受け関係を解析することができます。
文を -> 分けるには
文節に -> 分けるには
分けるには -> いいので
どう -> すれば
すれば -> いいので
いいので -> しょうか?
しょうか? -> 文末
これは係り受けの関係を解析するとともに、文を文節にわけることにも使えます。
リクエストUrlは
https://jlp.yahooapis.jp/DAService/V1/parse
パラメーターは以下のようになっています。
appid(必須) string アプリケーションID。
sentence(必須) string 解析対象のテキストです。
そこで
|
1 2 3 4 5 6 7 8 9 10 11 12 |
string url = "https://jlp.yahooapis.jp/DAService/V1/parse"; System.Net.WebClient wc = new System.Net.WebClient(); var ps = new System.Collections.Specialized.NameValueCollection(); ps.Add("appid", myYahooID); ps.Add("sentence", str); byte[] resData = wc.UploadValues(url, ps); wc.Dispose(); string resText = System.Text.Encoding.UTF8.GetString(resData); |
これで結果をうけとることができます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 |
<?xml version="1.0" encoding="UTF-8" ?> <ResultSet xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="urn:yahoo:jp:jlp:DAService" xsi:schemaLocation="urn:yahoo:jp:jlp:DAService > <Result> <ChunkList> <Chunk> <Id>0</Id> <Dependency>2</Dependency> <MorphemList> <Morphem> <Surface>文</Surface><Reading>ぶん</Reading><Baseform>文</Baseform><POS>名詞</POS><Feature>名詞,人名,*,文,ぶん,文</Feature> </Morphem> <Morphem> <Surface>を</Surface><Reading>を</Reading><Baseform>を</Baseform><POS>助詞</POS><Feature>助詞,格助詞,*,を,を,を</Feature> </Morphem> </MorphemList> </Chunk> <Chunk> <Id>1</Id> <Dependency>2</Dependency> <MorphemList> <Morphem> <Surface>文節</Surface><Reading>ぶんせつ</Reading><Baseform>文節</Baseform><POS>名詞</POS><Feature>名詞,名詞,*,文節,ぶんせつ,文節</Feature> </Morphem> <Morphem> <Surface>に</Surface><Reading>に</Reading><Baseform>に</Baseform><POS>助詞</POS><Feature>助詞,格助詞,*,に,に,に</Feature> </Morphem> </MorphemList> </Chunk> <Chunk> <Id>2</Id> <Dependency>5</Dependency> <MorphemList> <Morphem> <Surface>分ける</Surface><Reading>わけ</Reading><Baseform>分け</Baseform><POS>動詞</POS><Feature>動詞,一段,基本形,分ける,わけ,分け</Feature> </Morphem> <Morphem> <Surface>に</Surface><Reading>に</Reading><Baseform>に</Baseform><POS>助詞</POS><Feature>助詞,助詞副詞化,*,に,に,に</Feature> </Morphem> <Morphem> <Surface>は</Surface><Reading>は</Reading><Baseform>は</Baseform><POS>助詞</POS><Feature>助詞,係助詞,*,は,は,は</Feature> </Morphem> </MorphemList> </Chunk> <Chunk> <Id>3</Id> <Dependency>4</Dependency> <MorphemList> <Morphem> <Surface>どう</Surface><Reading>どう</Reading><Baseform>どう</Baseform><POS>副詞</POS><Feature>副詞,副詞,*,どう,どう,どう</Feature> </Morphem> </MorphemList> </Chunk> <Chunk> <Id>4</Id> <Dependency>5</Dependency> <MorphemList> <Morphem> <Surface>すれ</Surface><Reading>す</Reading><Baseform>す</Baseform><POS>動詞</POS><Feature>動詞,サ変する,体言接続,すれ,す,す</Feature> </Morphem> <Morphem> <Surface>ば</Surface><Reading>ば</Reading><Baseform>ば</Baseform><POS>助詞</POS><Feature>助詞,接続助詞,*,ば,ば,ば</Feature> </Morphem> </MorphemList> </Chunk> <Chunk> <Id>5</Id> <Dependency>6</Dependency> <MorphemList> <Morphem> <Surface>いい</Surface><Reading>い</Reading><Baseform>い</Baseform><POS>形容詞</POS><Feature>形容詞,形容,基本形,いい,い,い</Feature> </Morphem> <Morphem> <Surface>の</Surface><Reading>の</Reading><Baseform>の</Baseform><POS>助詞</POS><Feature>助詞,助詞その他,*,の,の,の</Feature> </Morphem> <Morphem> <Surface>で</Surface><Reading>で</Reading><Baseform>で</Baseform><POS>助詞</POS><Feature>助詞,格助詞,*,で,で,で</Feature> </Morphem> </MorphemList> </Chunk> <Chunk> <Id>6</Id> <Dependency>-1</Dependency> <MorphemList> <Morphem> <Surface>しょう</Surface><Reading>しょ</Reading><Baseform>しょ</Baseform><POS>動詞</POS><Feature>動詞,ワ五,基本形,しょう,しょ,しょ</Feature> </Morphem> <Morphem> <Surface>か</Surface><Reading>か</Reading><Baseform>か</Baseform><POS>助詞</POS><Feature>助詞,終助詞,*,か,か,か</Feature> </Morphem> <Morphem> <Surface>?</Surface><Reading>?</Reading><Baseform>?</Baseform><POS>特殊</POS><Feature>特殊,句点,*,?,?,?</Feature> </Morphem> </MorphemList> </Chunk> </ChunkList> </Result> </ResultSet> |
MorphemListのなかのSurfaceをつなげれば文節になります。他は必要ありません。
まず、XmlDocument.SelectNodesでMorphemListを取得して、あとはそのなかからMorphemを取得してSurfaceをつなぎ合わせます。得られた文節はリストに格納します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
var xmlDoc = new XmlDocument(); xmlDoc.LoadXml(resText); var nodes = xmlDoc.SelectNodes("//*[local-name()='MorphemList']"); List<string> vs = new List<string>(); foreach (XmlNode node in nodes) { var nodes1 = node.SelectNodes("*[local-name()='Morphem']"); string s = ""; foreach (XmlNode node1 in nodes1) { var node2 = node1.SelectSingleNode("*[local-name()='Surface']"); s += node2.InnerText; } vs.Add(s); } |
これをつなぎ合わせると文を文節に分解したときの結果が表示されます。
ただ一度に大量のデータをおくることができません。1リクエストの最大サイズは4KBに制限されています。そこで複数の文を解析する場合は分割して送ることになります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
public partial class Form1 : Form { private void button2_Click(object sender, EventArgs e) { string str = textBox1.Text; str = str.Replace("\r", ""); // 改行で分割する。 string[] strings = str.Split(new char[] { '\n' }, StringSplitOptions.RemoveEmptyEntries); List<string> vs = new List<string>(); int i = 0; foreach (string s in strings) { if (s == "") continue; vs.AddRange(GetTexts(s)); i++; } // 解析結果をつなぎ合わせて表示する richTextBox1.Text = String.Join("\n", vs.ToArray()); } List<string> GetTexts(string str) { string url = "https://jlp.yahooapis.jp/DAService/V1/parse"; System.Net.WebClient wc = new System.Net.WebClient(); //NameValueCollectionの作成 var ps = new System.Collections.Specialized.NameValueCollection(); //送信するデータ(フィールド名と値の組み合わせ)を追加 ps.Add("appid", myYahooID); ps.Add("sentence", str); //データを送信し、また受信する byte[] resData = wc.UploadValues(url, ps); wc.Dispose(); //受信したデータを表示する string resText = System.Text.Encoding.UTF8.GetString(resData); var xmlDoc = new XmlDocument(); xmlDoc.LoadXml(resText); var nodes = xmlDoc.SelectNodes("//*[local-name()='MorphemList']"); List<string> vs = new List<string>(); foreach (XmlNode node in nodes) { var nodes1 = node.SelectNodes("*[local-name()='Morphem']"); string s = ""; foreach (XmlNode node1 in nodes1) { var node2 = node1.SelectSingleNode("*[local-name()='Surface']"); s += node2.InnerText; } vs.Add(s); } return vs; } } |
日本語係り受け解析Web APIは、24時間以内で1つのアプリケーションIDにつき50000件のリクエストが上限となっています。やり過ぎには気をつけましょう。