前回はYahoo! JAPANの日本語形態素解析を使用しましたが、今回はMecabを使って形態素解析をおこないます。
まずMecabをインストールする必要があります。
http://taku910.github.io/mecab/#download
インストールするときに辞書の文字コードを設定することになりますが、このときはUTF-8を指定します。
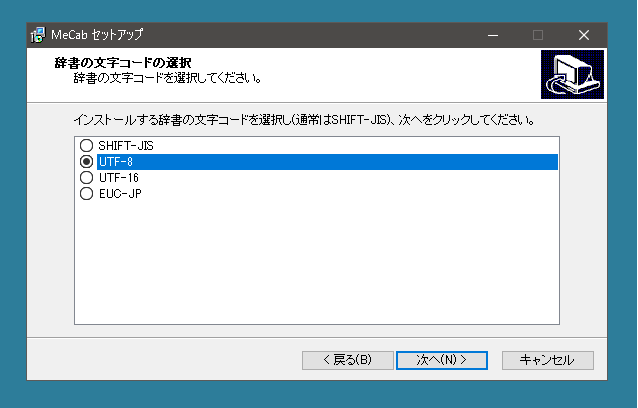
Mecabを使うためには辞書を作成する必要があります。ここではmecab-ipadic-NEologd を使います。
mecab-ipadic-NEologd は形態素解析エンジン MeCab と共に使う単語分かち書き辞書です。また週2回以上更新されているため、新しい単語や固有表現に強いのが特徴です。
ここを参考にした。
WindowsでNEologd辞書を比較的簡単に入れる方法ーユーザー辞書編 – Qiita
git for Windows 64bitをインストールしたあと、コマンドプロンプト立ち上げ以下のコマンドでNEologd辞書をダウンロードします。
|
1 |
git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git |
あとは、ダウンロードしたフォルダのなかにあるmecab-ipadic-neologd\seedフォルダの中にあるmecab-user-dict-seed.20200130.csv.xz(今回は2020年1月30日のものが最新だった)を解凍します。するとmecab-user-dict-seed.20200130.csvというファイルを得ることができます。
これをC:\Program Files (x86)\MeCab\dic\ipadicに移動させます。そしてファイル名をmecab-user-dict-seed-20200130.csvに変更します(mecab-user-dict-seed「.」20200130.csvをmecab-user-dict-seed「-」20200130.csvに変更する)。
そしてコマンドプロンプトで
|
1 |
mecab-dict-index -d "c:\Program Files (x86)\MeCab\dic\ipadic" -u "c:\Program Files (x86)\MeCab\dic\ipadic\mecab-user-dict-seed-20200130.dic" -f utf-8 -t utf-8 "c:\Program Files (x86)\MeCab\dic\ipadic\mecab-user-dict-seed-20200130.csv" |
するとc:\Program Files (x86)\MeCab\dic\ipadicフォルダのなかに、mecab-user-dict-seed-20200130.dicというファイルが作られます。
C#でMeCabを使うのであれば、NMeCabが便利です。これはMeCabの解析処理部分を、.NETライブラリとして移植したものです。 オリジナル版MeCabと同じ解析結果を得ることができます。
.NET形態素解析エンジンNMeCab プロジェクト日本語トップページ – OSDN
からダウンロードすることができます。解凍し、参照の追加でbinというフォルダのなかにあるLibNMeCab.dllを追加します。
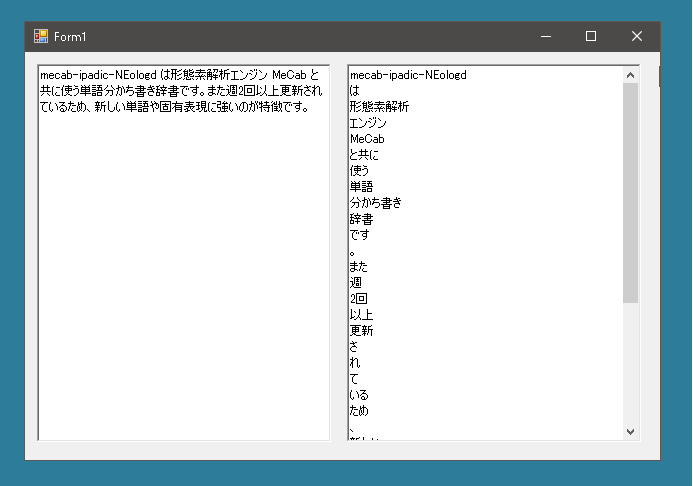
まず単純な分かち書きの方法から。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
public partial class Form1 : Form { string wakachi(string str) { StringBuilder sb = new StringBuilder(); try { MeCabParam param = new MeCabParam(); param.DicDir = @"C:\Program Files (x86)\MeCab\dic\ipadic"; // ここで先ほど作成したユーザー辞書のパスを指定する string[] dicPaths = new string[]{ @"C:\Program Files (x86)\MeCab\dic\ipadic\mecab-user-dict-seed-20200130.dic", // ユーザー辞書が他にもあるならここに書く。 }; param.UserDic = dicPaths; MeCabTagger t = MeCabTagger.Create(param); MeCabNode node = t.ParseToNode(str); while(node != null) { if(node.CharType > 0) { sb.Append(node.Surface + "\n"); } node = node.Next; } } catch(Exception ex) { MessageBox.Show(ex.Message); } return sb.ToString(); } private void button1_Click(object sender, EventArgs e) { richTextBox2.Text = wakachi(richTextBox1.Text); } } |
これで左のRichTextBoxに入力された文が分かち書きされた状態で右側のRichTextBoxに出力されます。
ではコピペチェックをするにはどうすればいいでしょうか?
前回はこのようなクラスに単語情報を格納して比較していました。
|
1 2 3 4 5 6 |
public class WordInfo { public string surface = ""; // 単語 public string baseform = ""; // 原形 public string pos = ""; // 品詞 } |
Mecabが返した情報から原形を取得するには上記のコードのこの部分
|
1 2 3 4 5 6 7 8 |
while(node != null) { if(node.CharType > 0) { sb.Append(node.Surface + "\n"); } node = node.Next; } |
node.Surfaceではなくnode.Featureに置き換えてみます。すると
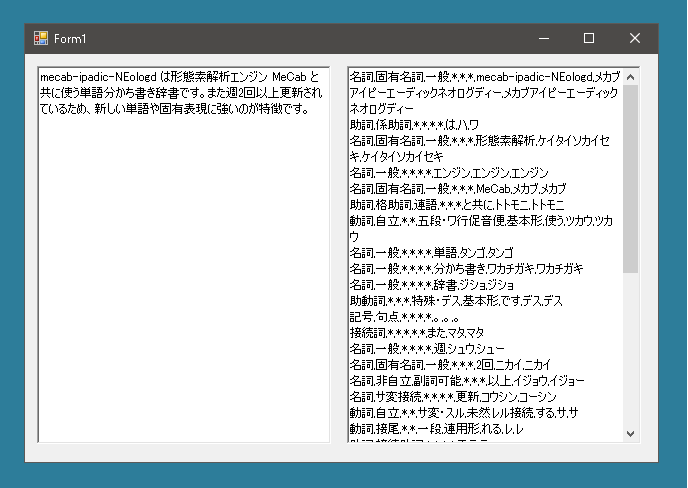
node.Surfaceによって得られる文字列をカンマで区切って7つめを取り出せばよいということがわかります。ただ存在しない場合があるので、このときはnode.Surfaceをそのまま使います。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
public partial class Form1 : Form { string GetGenkei(string surface, string feature) { string[] strings = feature.Split(new string[] { "," }, StringSplitOptions.None); if(strings[6] == "") return surface; else return strings[6]; } } |
以下は品詞を取得するメソッドです。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
public partial class Form1 : Form { string GetPos(string feature) { string[] strings = feature.Split(new string[] { "," }, StringSplitOptions.None); if(strings[0] == "") return ""; else return strings[0]; } } |
これらを使って入力された文章からWordInfoのリストを作成します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
public partial class Form1 : Form { List<WordInfo> GetWordInfos(string str) { List<WordInfo> wordInfos = new List<WordInfo>(); MeCabParam param = new MeCabParam(); param.DicDir = @"C:\Program Files (x86)\MeCab\dic\ipadic"; string[] dicPaths = new string[]{ @"C:\Program Files (x86)\MeCab\dic\ipadic\mecab-user-dict-seed-20200130.dic", }; param.UserDic = dicPaths; MeCabTagger t = MeCabTagger.Create(param); MeCabNode node = t.ParseToNode(str); while(node != null) { if(node.CharType > 0) { WordInfo info = new WordInfo(); info.baseform = GetGenkei(node.Surface, node.Feature); info.surface = node.Surface; info.pos = GetPos(node.Feature); wordInfos.Add(info); } node = node.Next; } return wordInfos; } } |
WordInfoのリストが作成されたら、2つの文章を比較して結果を表示します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
public partial class Form1 : Form { int SimilarRateFromWord(string oldText, string newText) { List<WordInfo> oldWords = GetWordInfos(oldText); List<WordInfo> newWords = GetWordInfos(newText); List<string> vs = new List<string>(); foreach(var info in newWords) { if(!oldWords.Any(x => x.baseform == info.baseform)) vs.Add(info.baseform); } return 100 - 100 * vs.Count / newWords.Count; } private void button1_Click(object sender, EventArgs e) { try { int similarRate = SimilarRateFromWord(richTextBox1.Text, richTextBox2.Text); string str = String.Format("コピペ率は {0} %です", similarRate); MessageBox.Show(str); } catch(Exception ex) { MessageBox.Show(ex.Message); } } } |
前回同様にコピペ判定をしてみましょう。
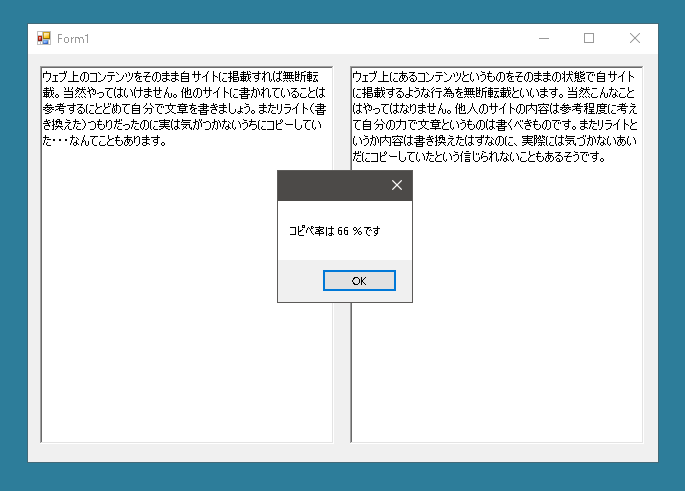
コピペ率は前回と同じくらいの値になりました。
