検索したときの結果をひとつひとつ調べるのは面倒くさくありませんか?
そこで今回は検索結果をまとめて取得するアプリをつくります。
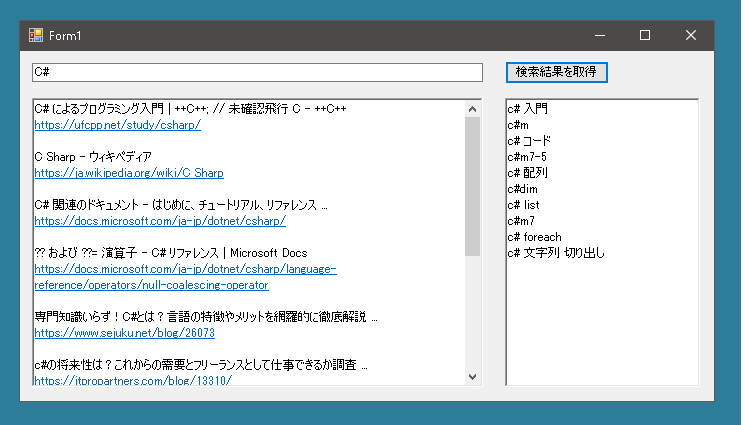
ところでこんな情報があります。
検索順位の自動チェックツールがなぜダメなのか – ブラックハットSEO大全 番外編1
自分のサイトの順位がどうなっているのか知りたいものです。そこで自動チェックツールというものがあるのですが、Googleは自動化されたクエリを禁止しています。ソフトウェアを使って自動化されたクエリを Google に送信し、検索結果におけるウェブページの順位を調べようとする行為はしてはいけないことになっているのです。
ではYahooはどうなのでしょうか? 自動化されたアクセスを明確に禁じる利用規約が見当たりませんが、やっぱりやり過ぎは禁物です。
ということでほどほどに使いましょう。サーバーに過度の負荷をかけるようなことはしてはいけません。
外観はこんな感じです。上のテキストボックスに検索したい単語を入力してボタンをおすと検索結果を表示させることができます。
またいわゆる虫眼鏡ワード(検索回数が多いキーワード)も取得できるようにしました。
Yahooの場合、検索結果を表示するページのurlは
基本形は
https://search.yahoo.co.jp/search?p=<検索したキーワード>
ですが、実際には文字列が続きます。
今回は
https://search.yahoo.co.jp/search?p=<検索したキーワード>
を使います。
まず検索した結果が表示されているページのhtmlを取得する必要があります。これは
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
string GetHtmlTextSearchWord(string searchWord) { string url = "https://search.yahoo.co.jp/search?p="; string urlEnc = System.Web.HttpUtility.UrlEncode(searchWord); url += urlEnc; HttpWebRequest req = (HttpWebRequest)HttpWebRequest.Create(url); string str; using(HttpWebResponse res = (HttpWebResponse)req.GetResponse()) using(Stream stream = res.GetResponseStream()) using(StreamReader sr = new StreamReader(stream)) { str = sr.ReadToEnd(); sr.Close(); } return str; } |
これでよさそうです。ところがこの内容をみてみると自分の手で検索したときとHTMLソースが異なっています。ずいぶんシンプルな形になっています。
これはどういうことかというと、取得されたテキストの最後の部分にありました。
セキュリティーアップグレードなどのアップグレードが終了しているブラウザ
CSS(カスケーディング・スタイル・シート)に対応していないブラウザ
CSSに対応しているが、Yahoo!検索の標準の検索結果ページをレイアウトするのに必要なCSSの対応が行われていないブラウザ
携帯端末に組み込まれたブラウザ・携帯端末向けブラウザ
これらを使って検索すると簡易版検索結果ページが表示されるのです。
さてここから必要なデータを抜き取るのですが、
検索結果の部分は
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
<div id="web"> <h2>ウェブ</h2> <ol> <li> <a href="url">ヒットしたページのタイトル</a> <div>リッチスニペット</div> <em>ページのurl</em> </li> <li> <a href="url">ヒットしたページのタイトル</a> <div>リッチスニペット</div> <em>ページのurl</em> </li> </ol> </div> <div id="rel"> <dl> <dt title="入力されたキーワードや、その組み合わせを機械的に収集・処理し、結果を自動的に表示しています">関連検索:</dt> <dd> <a href="url">虫眼鏡ワード</a>, <a href="url">虫眼鏡ワード</a>, <a href="url">虫眼鏡ワード</a>で検索 </dd> </dl> </div> |
となっています。
そこで<div id=”web”>の部分から</div>を抜き取り、そのなかから<a href = “url”>ページタイトル</a>の部分を抜けばよいということになります。
こんな処理をするときに便利なのがAngleSharpです。このページを参考にして使ってみました。
Visual Studioのメニュー[ツール] ⇒ [NuGetパッケージマネージャー] ⇒ [パッケージの管理]からAngleSharpをインストールしておきましょう。
まずurlがわかればHTMLソースを取得することができます。
|
1 2 3 4 5 6 7 8 9 10 |
HttpWebRequest req = (HttpWebRequest)HttpWebRequest.Create(url); string str; using(HttpWebResponse res = (HttpWebResponse)req.GetResponse()) using(Stream stream = res.GetResponseStream()) using(StreamReader sr = new StreamReader(stream)) { str = sr.ReadToEnd(); sr.Close(); } |
このHTMLソースから必要な情報を抜き出します。
|
1 2 3 4 5 6 |
using AngleSharp.Html.Parser; using AngleSharp.Html.Dom; HtmlParser parser = new HtmlParser(); IHtmlDocument htmlDocument = parser.ParseDocument(htmlText); var urlElements = htmlDocument.QuerySelectorAll("a"); |
とやればaタグの要素をすべて取得することができます。
あとはforeach文で以下のようにやればurlとアンカーテキストを取り出すことができます。
|
1 2 3 4 5 |
foreach(var urlElement in urlElements) { string text = urlElement.TextContent string url = urlElement.Attributes["href"].Value } |
まず検索してHtmlテキストを取得します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
public partial class Form1 : Form { string GetHtmlTextSearchWord(string searchWord) { string url = "https://search.yahoo.co.jp/search?p="; string urlEnc = System.Web.HttpUtility.UrlEncode(searchWord); url += urlEnc; HttpWebRequest req = (HttpWebRequest)HttpWebRequest.Create(url); string str; using(HttpWebResponse res = (HttpWebResponse)req.GetResponse()) using(Stream stream = res.GetResponseStream()) using(StreamReader sr = new StreamReader(stream)) { str = sr.ReadToEnd(); sr.Close(); } return str; } } |
つぎに上位サイトのタイトルとurlを取得するメソッドを示します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
using AngleSharp.Html.Parser; using AngleSharp.Html.Dom; public partial class Form1 : Form { // 上位サイトを取得する List<SiteInfo> GetRanking(string htmlText) { List<SiteInfo> siteInfos = new List<SiteInfo>(); IHtmlDocument htmlDocument = GetIHtmlDocument(htmlText); // id = "web"の要素を取得する。 string urlElementText = htmlDocument.GetElementById("web").InnerHtml; // aタグの要素を全て取得する。 IHtmlDocument htmlDocument1 = GetIHtmlDocument(urlElementText); var urlElements1 = htmlDocument1.QuerySelectorAll("a"); foreach(var a in urlElements1) { SiteInfo info = new SiteInfo(); info.title = a.TextContent; info.url = a.Attributes["href"].Value; siteInfos.Add(info); } return siteInfos; } } //上位表示されているサイトのタイトルとurlを管理するためのクラス public class SiteInfo { public string title; public string url; } |
つぎに虫眼鏡ワードを取得するメソッドを示します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
public partial class Form1 : Form { List<string> GetMushimeganeWords(string htmlText) { List<string> vs = new List<string>(); IHtmlDocument htmlDocument = GetIHtmlDocument(htmlText); // id = "rel"の要素を全て取得する。 string urlElementText = htmlDocument.GetElementById("rel").InnerHtml; // aタグの要素を全て取得する。 IHtmlDocument htmlDocument1 = GetIHtmlDocument(urlElementText); var urlElements1 = htmlDocument1.QuerySelectorAll("a"); foreach(var a in urlElements1) { vs.Add(a.TextContent); } return vs; } } |
検索ワードを入力してボタンを押せば、検索結果上位10サイトのタイトルとurl、そして虫眼鏡ワードがあれば表示されます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
public partial class Form1 : Form { private void button1_Click(object sender, EventArgs e) { string htmlText = GetHtmlTextSearchWord(textBox1.Text); StringBuilder sb = new StringBuilder(); List<SiteInfo> siteInfos = GetRanking(htmlText); foreach(SiteInfo info in siteInfos) { string str = String.Format("{0}\n{1}\n\n", info.title, info.url); sb.Append(str); } richTextBox1.Text = sb.ToString(); List<string> vs = GetMushimeganeWords(htmlText); richTextBox2.Text = String.Join("\n", vs.ToArray()); } } |
