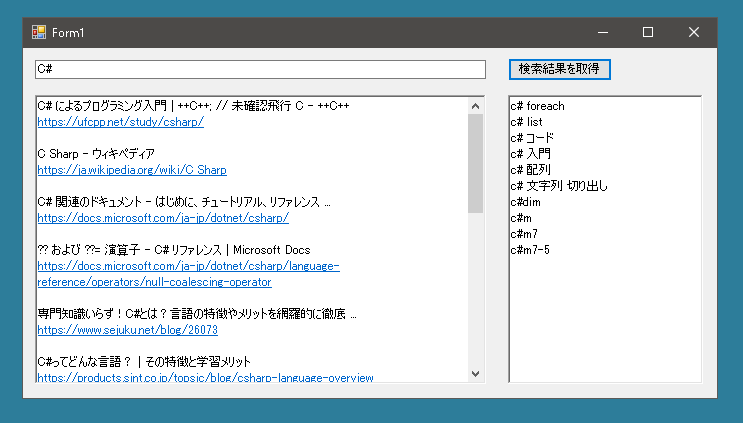
前回は検索結果を取得するためにHttpWebRequestクラスやHttpWebResponseクラスを使用しました。そしてこの場合は通常の検索結果が返されるのではなく簡易版検索結果ページが返されました。
https://search.yahoo.co.jp/legacy/help.htmlによると
セキュリティーアップグレードなどのアップグレードが終了しているブラウザ
CSS(カスケーディング・スタイル・シート)に対応していないブラウザ
CSSに対応しているが、Yahoo!検索の標準の検索結果ページをレイアウトするのに必要なCSSの対応が行われていないブラウザ
携帯端末に組み込まれたブラウザ・携帯端末向けブラウザ
の場合は簡易版検索結果ページが返されます。
そこで今回はWebBrowserコントロールをつかって検索結果を取得します。
いつの間にか仕様変更されてWebBrowserコントロールをつかっても取得されるのは簡易版検索結果ページです。そのため前回のページと同じ処理をすることになります。
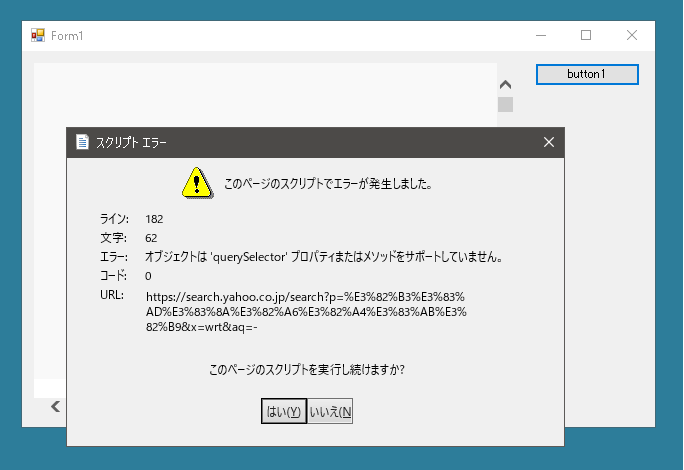
WebBrowserコントロールを使う場合、ScriptErrorsSuppressedプロパティをtrueにしておかないとスクリプトエラーを知らせるダイアログが何度も表示されます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
public partial class Form1 : Form { WebBrowser webBrowser1 = new WebBrowser(); public Form1() { InitializeComponent(); webBrowser1.ScriptErrorsSuppressed = true; webBrowser1.DocumentCompleted += WebBrowser1_DocumentCompleted; webBrowser1.Visible = false; } } |
WebBrowserは表示される必要はないので webBrowser1.Visible = false;にしています。
コントロールでドキュメントの読み込みが完了したらDocumentCompletedイベントが発生するので、そのときに処理ができるようにしておきます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
public partial class Form1 : Form { private void button1_Click(object sender, EventArgs e) { string url = "https://search.yahoo.co.jp/search?p="; string urlEnc = System.Web.HttpUtility.UrlEncode(textBox1.Text); url += urlEnc; webBrowser1.Navigate(url); } private void WebBrowser1_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e) { string htmlText = webBrowser1.DocumentText; // htmlTextをどうするか? } } |
HTMLコンテンツを取得することができたら、これを利用して検索結果を解析します。
まず上位10サイトのタイトルとurlを調べる方法ですが、検索結果が表示されている部分は
以下はPCで普通に検索した場合の結果です。簡易版検索結果ページとは異なります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
<div class="Contents__innerGroupBody"> <div class="sw-CardBase"> <div class="sw-Card Algo"> <section> <div class="sw-Card__section sw-Card__section--header"> <div class="sw-Card__headerSpace"> <div class="sw-Card__title sw-Card__title--cite"> <a href="url" onmousedown="省略" class="sw-Card__titleInner"> <h3 class="sw-Card__titleMain sw-Card__titleMain--clamp">ヒットしたページのタイトル</h3> <br> <div class="sw-Cite"> <cite>ufcpp.net/study/csharp/</cite> </div> </a> <span class="util-Delimiter">-</span> <a href="キャッシュのurl" onmousedown="省略" class="util-Text--subLink Algo__cache">キャッシュ</a> </div> </div> </div> <div class="sw-Card__section"> <div class="sw-Card__space"> <div class="sw-Card__floatContainer"> <p class="sw-Card__summary"> <span class="util-Text--sub">○年○月○日</span> リッチスニペット </div> </div> </div> </section> </div> </div> |
となっています。
必要なのは
|
1 |
<div class="sw-Card__title sw-Card__title--cite"> |
のつぎにあるurlとアンカーテキストだけです。
そこでclass = “sw-Card__title”の要素をすべて取得して、そのなかからさらにaタグの要素を最初のひとつだけ取得します。そしてその要素をInnerHtmlプロパティをつかってみてみると
|
1 2 3 4 5 |
<h3 class="sw-Card__titleMain sw-Card__titleMain--clamp">ヒットしたページのタイトル</h3> <br> <div class="sw-Cite"> <cite>ufcpp.net/study/csharp/</cite> </div> |
このようになっています。
そこで必要なのは class = “sw-Card__titleMain”の要素なので
|
1 2 3 4 5 6 7 8 |
IHtmlDocument htmlDocument2 = GetIHtmlDocument(selector.InnerHtml); var elements = htmlDocument2.GetElementsByClassName("sw-Card__titleMain"); string text = ""; foreach(var element1 in elements) text = element1.TextContent; if(text == "") text = selector.TextContent; |
とやって取得します。
またYahoo知恵袋やNAVERまとめブログなどのurlが3個くらいまとまって出てくることもあります。このときは class = “sw-Card__titleMain” はないので、aタグのアンカーテキストをそのまま取得しています。
上記の方法は使えません。前回の方法と同じ方法でないと結果を取得することはできません。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
public partial class Form1 : Form { // いまとなっては使えない // List<SiteInfo> GetTop10(string htmlText) // { // List<string> vs = new List<string>(); // IHtmlDocument htmlDocument = GetIHtmlDocument(htmlText); // // class = "sw-Card__title"の要素を全て取得する。 // var urlElements = htmlDocument.GetElementsByClassName("sw-Card__title"); // foreach (var element in urlElements) // { // IHtmlDocument htmlDocument1 = GetIHtmlDocument(element.InnerHtml); // // aタグの要素をひとつだけ取得する。 // var selector = htmlDocument1.QuerySelector("a"); // if (selector == null) // continue; // // urlに"listing.yahoo.co.jp"があるときは広告のリンクなので取得しない // if (selector.Attributes["href"].Value.IndexOf("listing.yahoo.co.jp") != -1) // continue; // // アンカーテキストを取得する (class = "sw-Card__titleMain"で囲まれた部分) // IHtmlDocument htmlDocument2 = GetIHtmlDocument(selector.InnerHtml); // var elements = htmlDocument2.GetElementsByClassName("sw-Card__titleMain"); // string text = ""; // foreach (var element1 in elements) // text = element1.TextContent; // if (text == "") // text = selector.TextContent; // SiteInfo info = new SiteInfo(); // info.title = text; // info.url = selector.Attributes["href"].Value; // ページのurl // vs.Add(info); // } // return vs; //} // ランキングを取得する List<SiteInfo> GetTop10(string htmlText) { List<SiteInfo> siteInfos = new List<SiteInfo>(); IHtmlDocument htmlDocument = GetIHtmlDocument(htmlText); // id = "web"の要素を取得する。 string urlElementText = htmlDocument.GetElementById("web").InnerHtml; // aタグの要素を全て取得する。 IHtmlDocument htmlDocument1 = GetIHtmlDocument(urlElementText); var urlElements1 = htmlDocument1.QuerySelectorAll("a"); foreach (var a in urlElements1) { SiteInfo info = new SiteInfo(); info.title = a.TextContent; info.url = a.Attributes["href"].Value; siteInfos.Add(info); } return siteInfos; } } |
次に虫眼鏡ワードを取得する方法ですが、Htmlを見ると虫眼鏡ワードの部分はこのようになっています。
以下はPCで普通に検索した場合の結果です。簡易版検索結果ページとは異なります。
|
1 2 3 4 5 6 7 8 9 10 11 |
<p class="util-Text--hidden" role="button">関連検索ワード</p> <ul class="Unit__list"> <li class="Unit__listItem"> <a href="url">虫眼鏡ワード</a> </li> <ul class="Unit__list"> <li class="Unit__listItem"> <a href="url">虫眼鏡ワード</a> </li> <li class="Unit__listItem">で検索</li> </ul> |
そこで class = “Unit__listItem”の要素をすべて取得して、それらのなかから aタグの要素をひとつだけ取得します。また虫眼鏡ワードは検索結果の上部と下部に表示されます。同じものは取り除いています。
上記の方法は使えません。前回の方法と同じ方法でないと結果を取得することはできません。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
public partial class Form1 : Form { // 虫眼鏡を取得する // いまとなっては使えない // List<string> GetMushimeganeWords1(string htmlText) // { // List<string> vs = new List<string>(); // IHtmlDocument htmlDocument = GetIHtmlDocument(htmlText); // // class = "Unit__listItem"の要素をすべて取得する。 // var urlElements = htmlDocument.GetElementsByClassName("Unit__listItem"); // foreach (var a in urlElements) // { // // aタグの要素をひとつだけ取得する。 // var urlElement = a.QuerySelector("a"); // if (urlElement == null) // continue; // // 改行は削除 // string word = urlElement.TextContent.Replace("\n", ""); // vs.Add(word); // } // return vs.Distinct().OrderBy(x => x).ToList(); //} // 虫眼鏡ワードを取得する List<string> GetMushimeganeWords(string htmlText) { List<string> vs = new List<string>(); IHtmlDocument htmlDocument = GetIHtmlDocument(htmlText); // id = "rel"の要素を全て取得する。 string urlElementText = htmlDocument.GetElementById("rel").InnerHtml; // aタグの要素を全て取得する。 IHtmlDocument htmlDocument1 = GetIHtmlDocument(urlElementText); var urlElements1 = htmlDocument1.QuerySelectorAll("a"); foreach (var a in urlElements1) { vs.Add(a.TextContent); } return vs; } } |
WebBrowserコントロールでドキュメントの読み込みが完了したら
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
public partial class Form1 : Form { private void WebBrowser1_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e) { string htmlText = webBrowser1.DocumentText; List<SiteInfo> siteInfos = GetTop10(htmlText); List<string> vs2 = GetMushimeganeWords1(htmlText); StringBuilder sb = new StringBuilder(); foreach(SiteInfo info in siteInfos) { string str = String.Format("{0}\n{1}\n\n", info.title, info.url); sb.Append(str); } richTextBox1.Text = sb.ToString(); richTextBox2.Text = String.Join("\n", vs2.ToArray()); } } |
