これはテキストファイルをドロップするとその内容がRichTextBoxに表示されるサンプルプログラムです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
public partial class Form1 : Form { public Form1() { InitializeComponent(); richTextBox1.DragOver += RichTextBox1_DragOver; richTextBox1.DragDrop += RichTextBox1_DragDrop; ; } private void RichTextBox1_DragDrop(object sender, DragEventArgs e) { if (e.Data.GetDataPresent(DataFormats.FileDrop)) { string[] files = (string[])e.Data.GetData(DataFormats.FileDrop); using (StreamReader sr = new StreamReader(files[0])) { richTextBox1.Text = sr.ReadToEnd(); } e.Effect = DragDropEffects.None; } } private void RichTextBox1_DragOver(object sender, DragEventArgs e) { if (e.Data.GetDataPresent(DataFormats.FileDrop)) e.Effect = DragDropEffects.All; } } |
これだと文字コードがSHIFT-JISの場合はうまく読み込めますが、UTF-8だと文字化けしてしまいます。
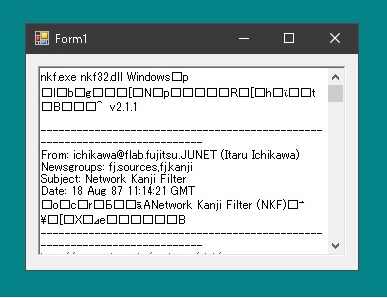
StreamReaderのコンストラクタで文字エンコーディングを設定すればいいのですが、ドロップされたテキストファイルがどうなっているのかはそのときにならないとわかりません。テキストファイルの文字コードを知る方法はないのでしょうか?
ここではnkf(Network Kanji Filter)を使った方法を紹介します。
まずnkf.exe nkf32.dll Windows 用を入手します。
ネットワーク用漢字コード変換フィルタ シフトJIS,EUC-JP,ISO-2022-JP,UTF-8,UTF-16
実行ファイルと同じフォルダにnkf32.dllをコピーしておきます。
そして
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 |
using System.Runtime.InteropServices; using System.IO; public partial class Form1 : Form { [System.Runtime.InteropServices.DllImport("nkf32.dll")] static extern int SetNkfOption(string optStr); [System.Runtime.InteropServices.DllImport("nkf32.dll")] unsafe static extern void NkfConvert(StringBuilder outStr, char* inStr); [System.Runtime.InteropServices.DllImport("nkf32.dll")] static extern int NkfGetKanjiCode(); public Encoding DetectEncoding(string path) { // -g: 自動判別の結果を出力する。 // -t: 何もしない。 SetNkfOption("-gt"); byte[] bytes; using (FileStream fs = new FileStream(path, FileMode.Open, FileAccess.Read)) { bytes = new byte[fs.Length]; fs.Read(bytes, 0, bytes.Length); } unsafe { fixed (byte* pbs = bytes) { StringBuilder strBldr = new StringBuilder(1); NkfConvert(strBldr, (char*)pbs); } } int nEnc = NkfGetKanjiCode(); // NkfGetKanjiCode() の戻り値に対応した値 const int SJIS = 0; const int EUC = 1; const int JIS = 2; const int UTF8 = 3; const int UTF16LE = 4; const int UTF16BE = 5; const int ASCII = 1001; // US-ASCII も ISO-2022-JP と判別される。ISO-2022-JP であれば ESC (0x1B) が含まれるので・・・ if (nEnc == JIS) { nEnc = ASCII; // US-ASCII と仮定する for (int i = 0; i < bytes.Length; i++) { if (bytes[i] == 0x1b) { nEnc = JIS; break; } } } switch (nEnc) { case SJIS: return Encoding.GetEncoding("shift_jis"); case EUC: return Encoding.GetEncoding("euc-jp"); case JIS: return Encoding.GetEncoding("iso-2022-jp"); case UTF8: return Encoding.UTF8; case UTF16LE: return Encoding.GetEncoding("utf-16"); case UTF16BE: return Encoding.GetEncoding("utf-16BE"); case ASCII: return Encoding.ASCII; default: return null; } } } |
これでテキストファイルのパスから文字コードを取得することができます。ただし対応しているのは
Shift_JIS
EUC-JP
ISO-2022-JP
UTF-8
UTF-16LE
UTF-16BE
だけです。これだけあれば十分かと・・・。
あとはファイルがドロップされたときに、
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
public partial class Form1 : Form { public Form1() { InitializeComponent(); richTextBox1.DragOver += RichTextBox1_DragOver; richTextBox1.DragDrop += RichTextBox1_DragDrop; ; } private void RichTextBox1_DragDrop(object sender, DragEventArgs e) { if (e.Data.GetDataPresent(DataFormats.FileDrop)) { string[] files = (string[])e.Data.GetData(DataFormats.FileDrop); var encoding = DetectEncoding(files[0]); if (encoding == null) { MessageBox.Show("文字コード不明"); e.Effect = DragDropEffects.None; return; } using (StreamReader sr = new StreamReader(files[0], encoding)) { richTextBox1.Text = sr.ReadToEnd(); } Text = encoding.EncodingName; e.Effect = DragDropEffects.None; } } } |
これで文字化けしないでファイルを開くことができるようになります。
