タイトルそのままです。YOUTUBEのチャンネル単位で動画のタイトルとURL、チャンネルを指定して丸ごとGETします。こんなことをして何が楽しいのかって? 実際にYOUTUBEの動画の分析の依頼は結構あるからです。
まずはターゲットのチャンネルにアクセス、そして「動画」のタブをクリック。urlは以下のような形式になっています。
https://www.youtube.com/channel/XXXX/videos
ここに表示されるものを丸ごとゲットしてしまえばいいのです。
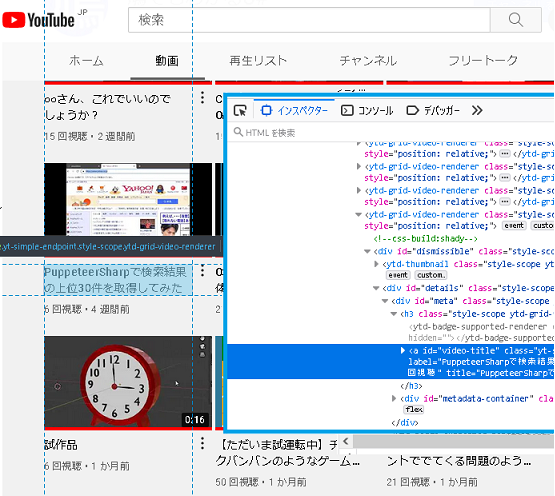
F12キーを押してインスペクターの部分をみてみると動画のタイトルと動画ページへのリンクはこの要素内に存在することがわかります。そこで右側のソースが選択されている部分を右クリックしてXPathを取得すると、
|
1 2 3 |
//*[@id="video-title"] // ↑ 短いのがうれしい! |
が取得されました。他の動画のタイトルとリンクもXPathはこれであることがわかります。
Contents
スクロールさせてすべて表示させる
動画はすべて表示されるわけではありません。検索結果を下にスクロールしておくとさらに古い動画が表示されます。実際にスクロールしないと情報を取得することができません。
ではどうするか? ここではPuppeteerSharpを使います。PuppeteerSharpで検索結果の上位30件を取得してみたにあるとおり、Seleniumを使ってもいいのですが、Selenium.Chrome.WebDriverはインストールされているGoogle Chromeのバージョンがあっていないとうまく動きません。だったらPuppeteerSharpを使ったほうがお手軽かもしれません。
といってもスクレイピング用のChromeがインストールされるため、初回の起動に時間がちょっとだけかかってしまう、実行ファイルがあるフォルダの容量が大きくなってしまうという欠点もあります。それでもPuppeteerSharpのほうが現在使用しているGoogle Chromeのバージョンアップの影響をうけないということでおすすめだと思うのです。
コードを書く
ではコードを書いていきましょう。
NuGetパッケージマネージャーをつかってPuppeteerSharpをインストールします。また結果をExcelファイルで保存したいのでClosedXMLもインストールします。
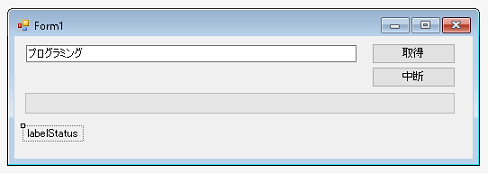
デザイナをつかってフォーム上にターゲットのurlを入力するためのテキストボックス、処理の進行状態を知るためのプログレスバー、取得開始をするためのボタン、処理が長引いた場合、途中でキャンセルするためのボタン、現段階で何件取得できているか表示させるラベルを配置します。
アプリケーションが開始されたらヘッドレスブラウザを起動します。このブラウザは見えないのですが、最初はどんな処理をしているのかが見えるようにしておいたほうがいいかもしれません。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
using PuppeteerSharp; // PuppeteerSharpを使うので必要 using ClosedXML.Excel; // 結果をExcelファイルで保存するため必要 public partial class Form1 : Form { public Form1() { InitializeComponent(); StartBrowsers(); } Page page1 = null; async void StartBrowsers() { startButton.Enabled = false; await new BrowserFetcher().DownloadAsync(BrowserFetcher.DefaultRevision); Browser browser = await Puppeteer.LaunchAsync(new LaunchOptions { // falseにするとヘッドレスブラウザがどのような処理をしているのかわかる Headless = true, }); page1 = await browser.NewPageAsync(); startButton.Enabled = true; } } |
結果はExcelファイルで保存する
実行ボタンが押されたときの処理を示します。urlがテキストボックスに入力されているかをチェックしたあと取得結果を保存するExcelファイルの保存場所を聞かれます。
保存先として適切な場所が指定されている場合はヘッドレスブラウザがそのUrlにアクセスして自作メソッドであるGetElementsWithScrollを呼び出します。このメソッドは自動的にスクロールしてページのデータを取得しようとします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
public partial class Form1 : Form { private async void GetVideoUrlButton_Click(object sender, EventArgs e) { string channelUrl = textBox1.Text; if (channelUrl == "") { MessageBox.Show("Urlを入力してください"); return; } string excelFilePath = GetSaveExelFilePath(); if (excelFilePath == "") return; startButton.Enabled = false; ElementHandle[] elements = await GetElementsWithScroll(channelUrl); List<Data> datas = await GetDataFromElements(elements); SaveExcel(excelFilePath, datas); MessageBox.Show("完了しました"); startButton.Enabled = true; } } |
GetSaveExelFilePathメソッドはファイルを保存するためのダイアログを表示してユーザーに保存する場所を選択させます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
public partial class Form1 : Form { string GetSaveExelFilePath() { string path = ""; SaveFileDialog dialog = new SaveFileDialog(); dialog.Filter = "Excelファイル(*.xlsx)|*.xlsx"; if (dialog.ShowDialog() == DialogResult.OK) path = dialog.FileName; dialog.Dispose(); return path; } } |
WheelAsyncメソッドでスクロールしながらElementHandleを取得する
GetElementsWithScrollメソッドはスクロールしながらデータを読み込み、そのなかにある要素を集めます。スクロールさせるためにはPuppeteerSharp.Page.Mouse.WheelAsyncメソッドを使えば簡単にできてしまいます。
基本的にすべての動画ページを集めたいのですが、スクロールすることでだんだんページの読み込み速度は下がります。また取得したデータが増えることでメモリの消費量も増えます。例外が発生したりページの読み込み速度が遅くなりすぎてループのなかで前回取得された件数と新しく取得された個数が同じ場合は全ページのデータを取得したとみなして(実はそうでないとしても)ループを抜けます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 |
public partial class Form1 : Form { private async Task<ElementHandle[]> GetElementsWithScroll(string channelUrl) { // キャンセルボタンがおされたらtrueになる isStop = false; await page1.GoToAsync(channelUrl); await System.Threading.Tasks.Task.Delay(2000); int oldCount = 0; Invoke((Action)(() => { progressBar1.Maximum = 100; progressBar1.Value = 0; })); int i = 0; ElementHandle[] elements = null; while (true) { try { // スクロールする i++; await page1.Mouse.WheelAsync(0, 1000 * i); await Task.Delay(1500); // スクロールしてしばらく待ちそのあと // XPathで指定された要素を取得する elements = await page1.XPathAsync("//*[@id=\"video-title\"]"); Invoke((Action)(() => { // XPathで指定された要素で現段階で取得された数を表示する labelStatus.Text = elements.Length.ToString() + "件取得"; })); // もしキャンセルボタンがおされていたらループを抜ける if (isStop) break; // 取得件数がスクロールする前と後では同じ場合、それ以上動画は存在しない if (oldCount == elements.Length) break; oldCount = elements.Length; } catch { // 例外発生のときはループを抜ける MessageBox.Show("例外発生!"); break; } } return elements; } } |
集めたElementHandleからデータを抜き出す
GetElementsWithScrollメソッドを実行して要素を集めることができたら、ここから動画タイトルと動画urlを抜き出します。抜き出したデータを格納するDataクラスはGetDataFromElementsメソッドのあとに示します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
public partial class Form1 : Form { async Task<List<Data>> GetDataFromElements(ElementHandle[] elements) { // プログレスバーを初期化する Invoke((Action)(() => { progressBar1.Maximum = elements.Length; progressBar1.Value = 0; })); // 返却するデータのリストを作成する List<Data> datas = new List<Data>(); // ループは何回まわったか? int i = 0; foreach (ElementHandle elementHandle in elements) { // アンカーテキストを取得する JSHandle jsHandle1 = await elementHandle.GetPropertyAsync("textContent"); string videoTitle = jsHandle1.ToString().Substring(9); // リンクを取得する JSHandle jsHandle2 = await elementHandle.GetPropertyAsync("href"); string videoUrl = jsHandle2.ToString().Substring(9); // Dataオブジェクトを生成してデータを格納し、リストに追加する Data data = new Data() { VideoTitle = videoTitle, VideoUrl = videoUrl }; datas.Add(data); // プログレスバーのValueを増やして処理が進行している様子を可視化する Invoke((Action)(() => { progressBar1.Value = i; i++; })); } // 終わったらプログレスバーを満タンの状態にする progressBar1.Value = progressBar1.Maximum; return datas; } } |
抜き出したデータを格納するDataクラスは以下のとおりです。タイトルと動画urlを格納するだけの簡単なものです。
|
1 2 3 4 5 |
public class Data { public string VideoTitle = ""; public string VideoUrl = ""; } |
結果をファイルとして保存する
Dataのリストが取得されたらこれを利用して動画タイトルと動画Urlが記載されたExcelファイルを作成します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
public partial class Form1 : Form { void SaveExcel(string excelPath, List<Data> datas) { using (var workbook = new XLWorkbook()) { var worksheet = workbook.Worksheets.Add("シート1"); worksheet.Cell(1, "A").Value = "動画タイトル"; worksheet.Cell(1, "B").Value = "動画Url"; int i = 2; foreach (Data data in datas) { worksheet.Cell(i, "A").Value = data.VideoTitle; worksheet.Cell(i, "B").Value = data.VideoUrl; i++; } workbook.SaveAs(excelPath); } } } |
実際にやってみるとわかりますが、スクロールすることでだんだんページの読み込みに時間がかかるようになるため、動画を大量にアップしているチャンネルだと途中で処理がおわってしまいます。
HikakinTVでどれくらいの動画urlを集めることができるかやってみましたが、実際には1000件くらいしか集めることができません。スクロールしたあとの待機時間を長めに設定してみましたが、やはり途中で止まってしまいます。またメモリーもそんなに積んでいないPCだと処理を続行することはできなくなります。
ではどうするか? 実はチャンネル内検索をすることで期間を指定して動画の検索することができます。これを次回は使ってみることにします。夏休み最終日(サラリーマンには関係ないか)、頑張っていきましょう。
