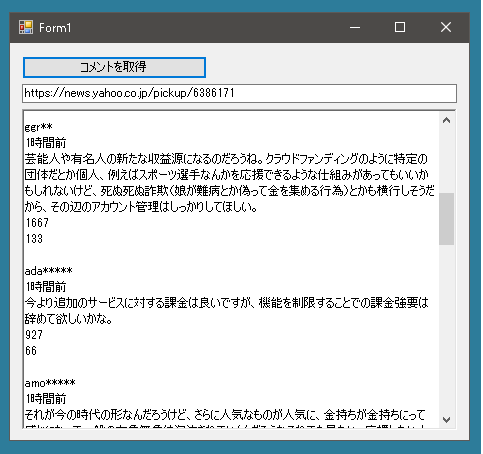
Yahooニュースのコメントをスクレイピングで取得できるかやってみました。
コメント欄にはiframeというフレームが使われているので、ニュースが掲載されているページのurlだけではうまくいきません。ブラウザをつかってフレームを開いてみるとそのurlはこのような構造になっています。長いので途中で改行しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
https://news.yahoo.co.jp/articles/15c618211ada7084648beffbf7f20ebe248fe0bd/comments のコメント https://news.yahoo.co.jp/comment/plugin/v1/full/? origin=https%3A%2F%2Fnews.yahoo.co.jp &sort=lost_points &order=desc &page=1 &type=t &topic_id=20210226-00000084-jij &space_id=2079510507 &content_id= &full_page_url=https%3A%2F%2Fheadlines.yahoo.co.jp%2Fcm%2Fmain%3Fd%3D20210226-00000084-jij-biz |
記事のtopic_idとspace_idとfull_page_urlがわかればここからコメントを取得することができそうです。
記事が掲載されているページのurlからtopic_idとspace_idとfull_page_urlを知ることはできるのでしょうか?
HTMLを調べてみるとこんな部分がみつかりました。topic_idとspace_idとfull_page_urlに相当する部分がすべて記述されています。
|
1 |
<div class="sc-gFaPwZ dLDnIh news-comment-plugin" data-device-type="pc" data-page-type="full" data-full-page-url="https://headlines.yahoo.co.jp/cm/main?d=20210226-00000084-jij-biz" data-topic-id="20210226-00000084-jij" data-space-id="2079510507" data-comment-num="10" data-flt="2" data-mtestid="mfn_3895=&mfn_5169=&mfn_5704=art039ct&mfn_5755=" data-bkt="art039ct"> |
news-comment-pluginというclassはここだけのようなので、ここから必要なデータを取得します。
こんな感じでコメントのurlを取得できます。またコメントが複数ページの場合、page=1の部分を変えればすべて取得できます。
|
1 2 3 4 5 6 7 8 9 10 |
string ret = "https://news.yahoo.co.jp/comment/plugin/v1/full/?"; ret += "origin=https%3A%2F%2Fnews.yahoo.co.jp"; ret += "&sort=lost_points"; ret += "&order=desc"; ret += "&page=1"; ret += "&type=t"; ret += "&topic_id=20210226-00000084-jij"; ret += "&space_id=2079510507"; ret += "&content_id="; ret += "&full_page_url=https%3A%2F%2Fheadlines.yahoo.co.jp%2Fcm%2Fmain%3Fd%3D20210226-00000084-jij-biz"; |
以下は記事のurlを引数にしてコメントのurlのリストを返すメソッドです。
パッケージマネージャーでAngleSharpをインストールしておいてください。また参照にSystem.Web.dllを追加しておいてください。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 |
using AngleSharp.Html.Parser; using AngleSharp.Html.Dom; using AngleSharp.Dom; using System.Net.Http; public partial class Form1 : Form { async Task<List<string>> GetCommentUrls(string url) { var htmlText = await HttpClient.GetStringAsync(url); HtmlParser parser = new HtmlParser(); IHtmlDocument htmlDocument = parser.ParseDocument(htmlText); IHtmlCollection<IElement> elements = htmlDocument.GetElementsByClassName("news-comment-plugin"); string topic_id = ""; string space_id = ""; string full_page_url = ""; if (elements.Count() == 0) return null; string outerHtml = elements[0].OuterHtml; int start = 0; int first = 0; int second = 0; int len = 0; start = outerHtml.IndexOf("data-full-page-url="); if (start == -1) return null; first = outerHtml.IndexOf("\"", start); if (first == -1) return null; second = outerHtml.IndexOf("\"", first + 1); if (second == -1) return null; len = second - first - 1; full_page_url = outerHtml.Substring(first + 1, len); full_page_url = System.Web.HttpUtility.UrlEncode(full_page_url); // System.Web.dllを追加 start = outerHtml.IndexOf("data-topic-id="); if (start == -1) return null; first = outerHtml.IndexOf("\"", start); if (first == -1) return null; second = outerHtml.IndexOf("\"", first + 1); if (second == -1) return null; len = second - first - 1; topic_id = outerHtml.Substring(first + 1, len); start = outerHtml.IndexOf("data-space-id="); if (start == -1) return null; first = outerHtml.IndexOf("\"", start); if (first == -1) return null; second = outerHtml.IndexOf("\"", first + 1); if (second == -1) return null; len = second - first - 1; space_id = outerHtml.Substring(first + 1, len); // コメントの最初のページのurl string ret = "https://news.yahoo.co.jp/comment/plugin/v1/full/?"; ret += "origin=https%3A%2F%2Fnews.yahoo.co.jp"; ret += "&sort=lost_points"; ret += "&order=desc"; ret += "&page=1"; ret += "&type=t"; ret += "&topic_id=" + topic_id; ret += "&space_id=" + space_id; ret += "&content_id="; ret += "&full_page_url=" + full_page_url; // コメントは全部で何ページあるのかを調べてurlのリストを返す var htmlText2 = await HttpClient.GetStringAsync(ret); IHtmlDocument htmlDocument2 = parser.ParseDocument(htmlText2); IElement elm = htmlDocument2.GetElementById("ft"); htmlDocument2 = parser.ParseDocument(elm.OuterHtml); IHtmlCollection<IElement> elms = htmlDocument2.GetElementsByTagName("span"); int count = elms.Count(); int commentCount = 0; string str = elms[count - 1].TextContent.Replace("/", ""); str = str.Replace("件", ""); List<string> vs = new List<string>(); if (count != 0) { try { commentCount = int.Parse(str); } catch { vs.Add(ret); return vs; } } else { vs.Add(ret); return vs; } for (int i = 1; i <= Math.Ceiling(commentCount / 10.0); i++) { string ret2 = "https://news.yahoo.co.jp/comment/plugin/v1/full/?"; ret2 += "origin=https%3A%2F%2Fnews.yahoo.co.jp"; ret2 += "&sort=lost_points"; ret2 += "&order=desc"; ret2 += "&page=" + i.ToString(); ret2 += "&type=t"; ret2 += "&topic_id=" + topic_id; ret2 += "&space_id=" + space_id; ret2 += "&content_id="; ret2 += "&full_page_url=" + full_page_url; vs.Add(ret2); } return vs; } } |
コメントのurlのリストが取得できたら実際にアクセスして名前、時刻、コメントの内容、そう思う思わないの数を文字列として取得します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
public partial class Form1 : Form { async Task<string> GetComments(string url) { List<string> comurls = await GetCommentUrls(url); if (comurls == null) return ""; var htmlText = await HttpClient.GetStringAsync(comurls[0]); HtmlParser parser = new HtmlParser(); IHtmlDocument htmlDocument = parser.ParseDocument(htmlText); IHtmlCollection<IElement> elements = htmlDocument.GetElementsByClassName("root"); StringBuilder sb = new StringBuilder(); foreach (IElement elm in elements) { string name = ""; string date = ""; string comment = ""; string agree = ""; string disagree = ""; IHtmlDocument htmlDocument2 = parser.ParseDocument(elm.InnerHtml); IHtmlCollection<IElement> elmNames = htmlDocument2.GetElementsByClassName("yjxName"); if (elmNames.Count() != 0) name = elmNames[0].TextContent; IHtmlCollection<IElement> elmDates = htmlDocument2.GetElementsByClassName("yjxDate"); if (elmDates.Count() != 0) date = elmDates[0].TextContent; IHtmlCollection<IElement> elmCmts = htmlDocument2.GetElementsByClassName("yjxComment"); if (elmCmts.Count() != 0) comment = elmCmts[0].TextContent; IHtmlCollection<IElement> elmAgrees = htmlDocument2.GetElementsByClassName("agreeBtn"); if (elmAgrees.Count() != 0) { IHtmlDocument htmlDocument3 = parser.ParseDocument(elmAgrees[0].InnerHtml); IHtmlCollection<IElement> elmNum = htmlDocument3.GetElementsByClassName("userNum"); agree = elmNum[0].TextContent; } IHtmlCollection<IElement> elmDisagrees = htmlDocument2.GetElementsByClassName("disagreeBtn"); if (elmDisagrees.Count() != 0) { IHtmlDocument htmlDocument3 = parser.ParseDocument(elmDisagrees[0].InnerHtml); IHtmlCollection<IElement> elmNum = htmlDocument3.GetElementsByClassName("userNum"); disagree = elmNum[0].TextContent; } sb.Append(name.Trim() + "\n"); sb.Append(date.Trim() + "\n"); sb.Append(comment.Trim() + "\n"); sb.Append(agree.Trim() + "\n"); sb.Append(disagree.Trim() + "\n"); sb.Append("\n"); } return sb.ToString(); } } |
こんな感じで取得できます。
|
1 2 3 4 5 6 7 8 |
public partial class Form1 : Form { private async void button3_Click(object sender, EventArgs e) { string url = textBox1.Text; richTextBox1.Text = await GetComments(url); } } |
