PCのCPU性能の向上に伴い、パソコン上で文字を認識するOCR(Optical Character Recognition/Reader)ソフトが商品化されています。今回は無料で使えるTesseractを使います。
使い方
VisualStudioであれば
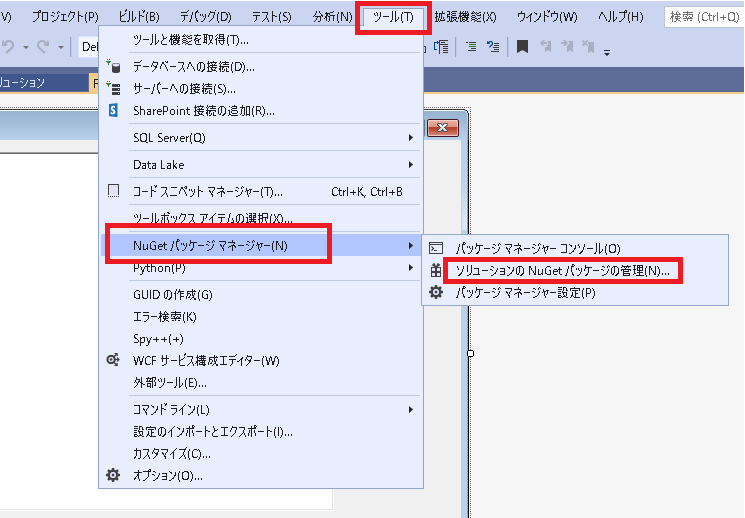
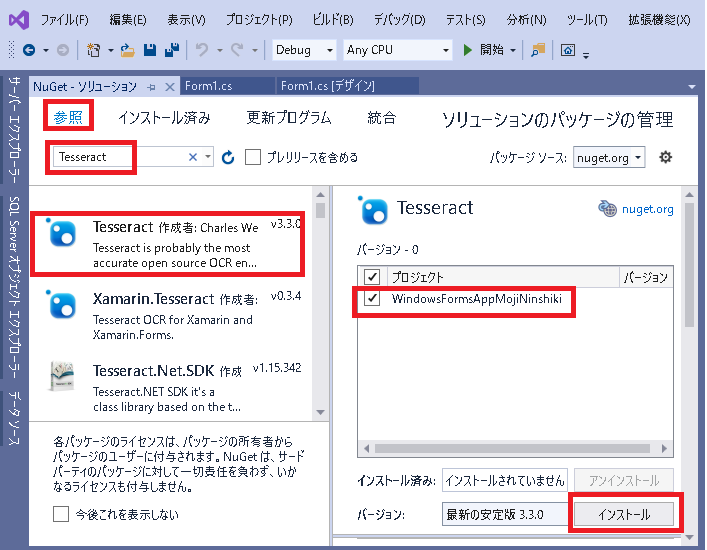
インストールをクリックしたらビルドしてみます。
すると実行ファイルができるフォルダにdllファイルとフォルダが作成されているはずです。
Tesseractを使うのであれば、さらに言語データが必要になります。
英語:tesseract-ocr-3.02.eng.tar.gz
日本語:tesseract-ocr-3.02.jpn.tar.gz
「tesseract-ocr-3.02.jpn.tar.gz」で検索したらダウンロードできるサイトがあったのでダウンロードしました。解凍したら「tessdata」というフォルダがあるので、これをどこか適当な場所にコピーします。今回はCドライブの直下にコピーしました。
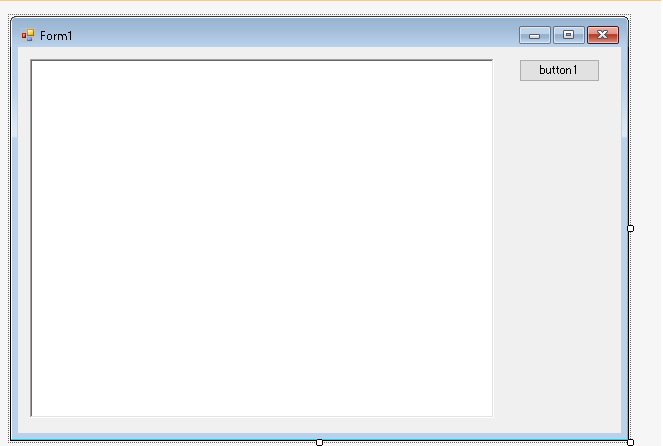
アプリの外観はこんな感じです。左にあるのはRichTextBoxです。そしてボタンをクリックしたときの処理として以下を書き加えます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
public partial class Form1 : Form { private void button1_Click(object sender, EventArgs e) { richTextBox1.Text = GetTextFromImage(); } string GetTextFromImage() { //言語ファイルの格納先(tessdataフォルダのパス) string langPath = @"c:\tessdata"; //言語(日本語なら"jpn") string lngStr = "jpn"; // 文字認識させるBitmapを作成する Bitmap bitmap = GetBitmap(); // 後述 using(var tesseract = new Tesseract.TesseractEngine(langPath, lngStr)) { // OCRの実行 Tesseract.Page page = tesseract.Process(bitmap); return page.GetText(); } } } |
page.GetText()はString型を返すので、これをRichTextBoxに表示させればよいということになります。
注意しなければならないのはBitmap画像は24bitBitmapでなければならないということです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
public partial class Form1 : Form { Bitmap GetBitmap() { Image img = Clipboard.GetImage(); Bitmap bitmap = new Bitmap(img.Width, img.Height, System.Drawing.Imaging.PixelFormat.Format24bppRgb); Graphics graphics = Graphics.FromImage(bitmap); graphics.DrawImage(img, new PointF(0, 0)); graphics.Dispose(); return bitmap; } } |
これで一応できるはずです。
ためしにやってみると・・・

予約商品入荷後、
順次配送いたします〝

誰でも! 対蒙の人気ストアで買ぅと最大+ー。%
うーん、多少おかしなところがあるけど読めているようです。
ただ複雑な画像になると読めません。

なにも表示されません。
画像になった文字を読むためには細かく分割したほうが精度が高くなるということがわかります。
