Pythonのライブラリで文章の感情分析ができるということなのでやってみました。ただPythonはあまり得意ではないので全体をPythonで書きたくないです。他の言語でも利用できるようなAPIの部分だけPythonでつくります。
参考にしたページ:AIで文章から感情分析するアプリの作成 – Qiita
日本語文章の文全体を感情分析する
まずはPythonでプログラミング。以下をpipコマンドでインストールします。
|
1 2 3 4 |
pip install flask pip install torch torchvision pip install transformers[ja] pip install sentencepiece |
試しに以下のコードを実行してみるとうまくいきません。なぜかlibmecab.dllがC:\Users\<ユーザー名>\AppData\Roaming\Python\lib\site-packages\fugashiにインストールされてしまうのです。これに関してはlibmecab.dllをC:\Users\<ユーザー名>\AppData\Roaming\Python\Python39\site-packages\fugashiにコピーすることで解決します。
libmecab.dllを適切な位置にコピーしたら以下のコードを実行してみましょう。「C#をつかえば簡単にプログラミングができます。さあ、あなたもLet’s C#」だと「ポジティブ:95.65」という結果になります。
文字数には上限があり、512文字です。
app.py
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
from flask import * from transformers import pipeline, AutoModelForSequenceClassification, BertJapaneseTokenizer model = AutoModelForSequenceClassification.from_pretrained('daigo/bert-base-japanese-sentiment') tokenizer = BertJapaneseTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking') nlp = pipeline("sentiment-analysis",model=model,tokenizer=tokenizer) app = Flask(__name__) @app.route("/", methods=["GET", "POST"]) def index_page(): if request.method == "GET": return """ 文章を入力してください。ネガティブかポジティプか判定します <form action="/" method="POST"> <input name="str"></input> </form> """ else: try: str = request.form["str"] result = nlp(str) return """ <form action="/" method="POST"> <input name="str"></input> </form> {}<br>{}:{} """.format(str, result[0]["label"], round(result[0]["score"]*100,2)) except: return """ エラーが発生しました。文章を変更してお試しください。 <form action="/" method="POST"> <input name="str"></input> </form>""" if __name__ == "__main__": app.run(debug=True, host='0.0.0.0', port=8888, threaded=True) # サーバー上で実行するときはdebug=Falseにしないと実行できない |
一文ごとに感情分析する
少し機能を拡張して文全体と一文ごとの両方で感情分析できるようにします。
templatesフォルダを作成してなかにindex.htmlをつくります。
templates\index.html
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
<!DOCTYPE html> <html lang="ja"> <head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>感情分析</title> <style> td { border:1px solid #333; max-width:300px; padding:5px; } #submit { margin-top:10px; width:100px; } </style> </head> <body> 文章を入力してEnterキーを入力してください。ネガティブかポジティプか判定します <form action="/" method="POST"> <textarea name="str" rows="10" cols="50" maxlength="400"></textarea><br> <input type="submit" id="submit" value="解析する" /> </form> <br> {{ result }} </body> </html> |
テキストエリアにある文字列を「。」で区切って配列に変換します。また改行がある部分も「。」があるものと見なしています。そして一文ごとの評価と文全体の評価をtableタグで返します。
app.py
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
from flask import * from transformers import pipeline, AutoModelForSequenceClassification, BertJapaneseTokenizer model = AutoModelForSequenceClassification.from_pretrained('daigo/bert-base-japanese-sentiment') tokenizer = BertJapaneseTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking') nlp = pipeline("sentiment-analysis",model=model,tokenizer=tokenizer) app = Flask(__name__) @app.route("/", methods=["GET", "POST"]) def index_page(): if request.method == "GET": return render_template("index.html", result= '') else: try: str = request.form["str"] max_length = 400 # 512が限界 if len(str) > max_length: str = sentence[0:max_length] str = str.replace(" ", "") str = str.replace("\r\n", "\n") str = str.replace("\n", "。") # 改行は「。」とみなす arr = str.split('。') arr = list(filter(None, arr)) # 空白行は取り除く rets = nlp(arr) result = "" result += "<table>" index = 0 for ret in rets: if arr[index] == "": continue result += "<tr>" result += "<td>{}</td>".format(arr[index]) label = ret["label"] score = ret["score"] result += "<td>{}</td><td>{}%</td>".format(label, round(score*100,2)) result += "</tr>" index += 1 ret = nlp(request.form["str"]) result += "<tr>" result += "<td>総合評価</td>" result += "<td>{}</td><td>{}%</td>".format(ret[0]["label"], round(ret[0]["score"]*100,2)) result += "</tr>" result += "</table>" result = Markup(result) return render_template("index.html", result= result) except: result += "エラーが発生しました。文章を変更してお試しください。" return render_template("index.html", result= result) if __name__ == "__main__": app.run(debug=True, host='0.0.0.0', port=8888, threaded=True) |
APIをつくる
次に他のアプリからでも使えるようにAPIにして別のページから呼び出せるようにします。APIはJson形式で文をうけとり、文を「。」で配列に分割します。そして結果をJson形式で返します。そのときクロスオリジン要求をブロックされないようにする必要があります。そのために flask_cors をインストールしておきます。
pip install flask_cors
|
1 2 3 4 5 6 |
from flask import * from flask_cors import CORS # CORSを許可するために必要 app = Flask(__name__) # CORS(app) # これだとどこからでも許可されるのでやめたほうがよさそう CORS(app, resources={r'/api-test': {'origins': 'https://lets-csharp.com'}}) # 限定する場合 |
ではAPI部分のソースコードを示します。
app.py
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
from flask import * from transformers import pipeline, AutoModelForSequenceClassification, BertJapaneseTokenizer model = AutoModelForSequenceClassification.from_pretrained('daigo/bert-base-japanese-sentiment') tokenizer = BertJapaneseTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking') nlp = pipeline("sentiment-analysis",model=model,tokenizer=tokenizer) from flask_cors import CORS # CORSを許可 app = Flask(__name__) CORS(app, resources={r'/api-test': {'origins': 'https://lets-csharp.com'}}) # CORSを許可 @app.route("/api-test", methods=["POST"]) def api_test_page(): if request.method == "POST": json = request.get_json() sentence = json['sentence'] max_length = 400 # 512が限界 if len(sentence) > max_length: sentence = sentence[0:max_length] str = sentence.replace(" ", "") str = str.replace(" ", "") str = str.replace("\r\n", "\n") str = str.replace("\n", "。") arr = str.split('。') arr = list(filter(None, arr)) rets = nlp(arr) index = 0 results = [] for ret in rets: if arr[index] == "": continue label = ret["label"] score = ret["score"] result = { "sentence": arr[index], "label": label, "score": score, } results.append(result) index += 1 ret = nlp(sentence) label = ret[0]["label"] score = ret[0]["score"] result = { "label": label, "score": score, "results":results, } return jsonify(result) if __name__ == "__main__": app.run(debug=True, host='0.0.0.0', port=8888, threaded=True) |
APIを使う
次にこのAPIを使って文の感情分析をできるようにします。
以下のようなHTMLを作成します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
<!DOCTYPE html> <html lang="ja"> <head> <meta charset="UTF-8"> <title>日本語文章の感情分析APIをつくって感情分析する</title> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <style> #container { margin: 50px; width: 100%; max-width: 600px; } .button { width: 100px; margin-top: 20px; margin-bottom: 20px; } td { border:1px solid #333; padding:5px; } </style> </head> <body> <div id = "container"> <p>日本語文章の感情分析をおこないます。</p> <div><textarea id="text" rows="10" cols="50" maxlength="400"></textarea></div> <div> <button type="button" class ="button" onclick="OnClick()">解析</button> <button type="button" class ="button" onclick="Clear()">クリア</button> </div> <div id="result"> </div> </div> <script src="https://ajax.googleapis.com/ajax/libs/jquery/1.9.1/jquery.min.js"></script> <script src="app.js"></script> </body> </html> |
JavaScriptで以下のような処理をおこないます。
入力されたデータと解析結果をクリアします。
app.js
|
1 2 3 4 |
function Clear(){ document.getElementById('text').value = ''; document.getElementById('result').innerText = ''; } |
[解析]ボタンが押されたらデータをJson形式に変換してpostします。そして解析結果をJson形式でうけとります。
app.js
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
function OnClick(){ let text = document.getElementById('text').value; let obj = { "sentence":text } var json_text = JSON.stringify(obj); console.log(json_text); jQuery.ajax({ type:"post", url:"http://localhost:8888/api-test", // POST送信先のURL data:json_text, // JSONデータ本体 contentType: 'application/json', // リクエストの Content-Type dataType: "json", // レスポンスをJSONとしてパースする success: function(data) { // 200 OK時 ShowResult(data); }, error: function() { // HTTPエラー時 alert("失敗:Server Error. Please try again later."); } }); } |
データが返されたらtableタグで結果を表示します。
app.js
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
function ShowResult(data){ document.getElementById('result').innerText = ''; let html = ''; html += '<table>'; html += `<tr>`; html += `<td>文</td>`; html += `<td>評価</td>`; html += `<td>スコア</td>`; html += `</tr>`; html += `<tr>`; html += `<td>総合評価</td>`; html += `<td>${data.label}</td>`; html += `<td>${data.score}</td>`; html += `</tr>`; for(let i=0; i<data.results.length; i++){ html += `<tr>`; html += `<td>${data.results[i].sentence}</td>`; html += `<td>${data.results[i].label}</td>`; html += `<td>${data.results[i].score}</td>`; html += `</tr>`; } html += '</table>'; document.getElementById('result').innerHTML = html; } |
あとはこれをサーバー上に公開するだけ♪と思っていたのですが、問題発生!
けっこうメモリーを消費してくれるのです。
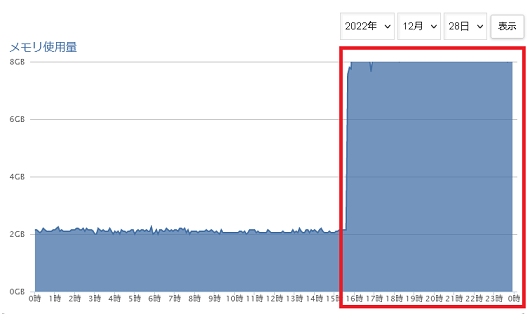
あわててアプリを停止させましたがメモリ使用量がさがってくれません(いつもは2GB前後)。
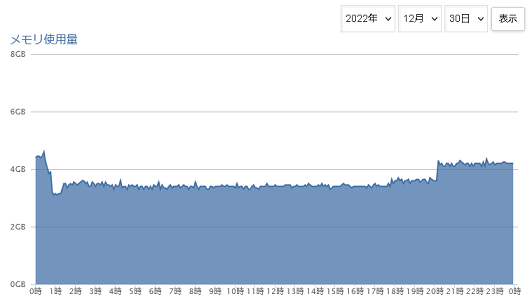
しかたなく関連するライブラリをアンインストールすることにしました。それと同時に使用メモリが急激にさがっています。
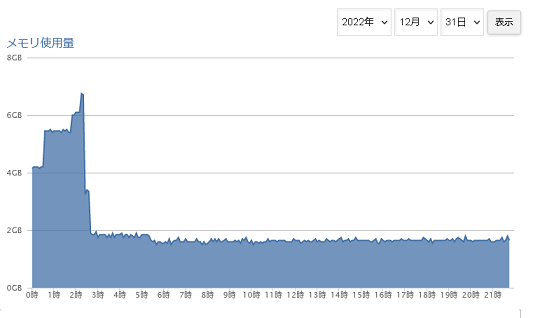
専用サーバーならやりたい放題しても誰からも文句はいわれませんが、共用サーバーなのでしかたないです。実験するときはローカルで実験してください。
