画像掲示板をみていたら面白そうな写真を多数発見。でもひとつひとつ保存なんてやってられない。そんなときに重宝するページ上の画像を一括ダウンロードするツールをつくってみました。
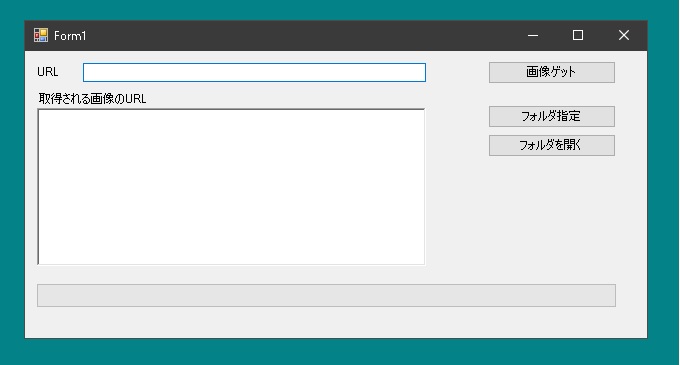
まず目的の画像が貼っているurlを入力。するとHTMLソースを解析してjpgファイルへのリンクを探して保存するというものです。
まず入力されたurlからHTMLソースを取得します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
public partial class Form1 : Form { string GetHtmlText(string url) { HttpWebRequest req = (HttpWebRequest)HttpWebRequest.Create(url); HttpWebResponse res = (HttpWebResponse)req.GetResponse(); var stream = res.GetResponseStream(); StreamReader sr = new StreamReader(stream); string str = sr.ReadToEnd(); sr.Close(); return str; } } |
これでHTMLソースは取得できるので、これを解析して画像をさがします。
リンクは
|
1 |
<a href="XXXXXXX.jpg"><img src="xxxxxx.jpg" alt="サンプル"></a> |
という形になっています。xxxxxx.jpgはサムネイルの小さな画像で目的の画像のurlはXXXXXXX.jpgの部分です。
ただ
|
1 |
<a target="_blank" href="XXXXXXX.jpg" rel="noopener noreferrer"><img src="xxxxxx.jpg" alt="サンプル"></a> |
のような形になっている場合もあります。aのあとにhrefがすぐにくるとは限りません。それ以外にもrel=”nofollow”というタグが入っていることもあります。ほしいのは<a href=”XXXXXXX.jpg”>の部分だけです。それから<a href = “XXXXXXX.jpg”>と=の前後にスペースが入っている場合もあります。
ではどうするか? まずGetHtmlTextメソッドで取得したテキストを分解してしまいましょう。
|
1 |
string[] vs = htmlText.Split(new string[] { "href =", "href=" }, StringSplitOptions.RemoveEmptyEntries); |
これで分解された文字列の先頭は
“~”
という形になっているはずです。そして”~”の間を抜くことができればリンク先を取得することができそうです。
ただリンク先はjpgファイルとは限りません。そこで
最初にみつかった「”」から2番目の「”」の間を抜き出し(「”」が2つ以上存在しない文字列は捨てる)、抜き出した文字列の先頭が「http」であるかどうか調べます。httpでもhttpsでも先頭の4文字はhttpです。
次に文字列の最後に着目します。「.jpg」で終わっているかどうか。
String.LastIndexOf(“.jpg”);
String.LastIndexOf(“.”);
両方を調べて値が同じなら抜き出したurlの最後は.jpgになっていると考えてよさそうです。
そこでhtmlソースからjpgファイルのurlを抜き出すメソッドとして以下のようなものを作りました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
public partial class Form1 : Form { List<string> GetJpgUrls(string htmlText) { List<string> ret = new List<string>(); string[] vs = htmlText.Split(new string[] { "href =", "href=" }, StringSplitOptions.RemoveEmptyEntries); foreach (var s in vs) { int i1 = s.IndexOf("\""); if (i1 == -1) continue; int i2 = s.IndexOf("\"", i1 + 1); if (i2 == -1) continue; string url1 = s.Substring(i1 + 1, i2 - i1 - 1); if (url1.Length < 5) continue; if (url1.Substring(0, 4) != "http") continue; int i3 = url1.LastIndexOf(".jpg"); int i4 = url1.LastIndexOf("."); if (i3 == i4) { ret.Add(url1); } } return ret; } } |
jpgのurlがわかったらダウンロードしてファイルとして保存します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
public partial class Form1 : Form { public bool SaveFileFromUrl(string filePath, string url) { var ms = new MemoryStream(); try { var req = (HttpWebRequest)WebRequest.Create(url); var res = (HttpWebResponse)req.GetResponse(); var st = res.GetResponseStream(); byte[] buf = new byte[1000]; while (true) { // ストリームから一時バッファに読み込む int read = st.Read(buf, 0, buf.Length); if (read > 0) { // 一時バッファの内容をメモリ・ストリームに書き込む ms.Write(buf, 0, read); } else { break; } } File.WriteAllBytes(filePath, ms.ToArray()); return true; } catch { return false; } } } |
string GetHtmlText(string url)
List<string> GetJpgUrls(string htmlText)
public bool SaveFileFromUrl(string filePath, string url)
この3つがあればサイト上の画像を一括ダウンロードできそうです。
あとはボタンを押したら処理を開始できるようにするだけです。
ファイルは連番になるようにしています。またダウンロードしようとしているファイルのurlとどこまで処理が完了したかわかるようにプログレスバーを表示させています。
それからサーバーに負荷をかけないように10個ダウンロードしたら3秒間停止するようにしています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
public partial class Form1 : Form { private void buttonGazouGet_Click(object sender, EventArgs e) { if (!Directory.Exists(folderPath)) return; Task.Run(()=> { GetJpgs(); }); } void GetJpgs() { string url = textBox1.Text; string str = GetHtmlText(url); List<string> jpgUrls = GetJpgUrls(str); richTextBox1.Text = String.Join("\n", jpgUrls.ToArray()); int i = 0; progressBar1.Value = 0; progressBar1.Maximum = jpgUrls.Count; foreach (string url0 in jpgUrls) { i++; progressBar1.Value++; string filepath = String.Format("{0}\\{1:000}.jpg", folderPath, i); SaveFileFromUrl(filepath, url0); if (i % 10 == 0) System.Threading.Thread.Sleep(3000); } progressBar1.Value = 0; } } |
